Frugal AI, How we make Efficient AI Algorithms with Low Resources and Less Data
⎯ Article by D. Antony J R In this new era of AI, it's not who got the big brains but who got the most resources. In this article we see on how we make AI/ML solutions for our clients without spending a fortune.As the newly appointed Chief Technology Officer (apart from the fancy title, it just means more work) at IBC VectorMind Labs, I was responsible for a platform and infrastructure to experiment, collaborate and deploy AI/ML models for our clients (also some of our products). This is especially challenging because I had to do this in a very tight budget, not that we can't afford it but rather I just wanted to see if we can make it cheap, I mean don't we all love a free lunch. But on a serious note, we don't want to end up with a $90,000 cloud invoice just because we forgot something over a busy Friday night.

Jokes apart, this is now a reality, don't trust me, I advice you to watch this fun video from Fireship.
But the actual fun starts when business owners realize that AI costs a lot of money just for the compute and AI bubble is still expanding like crazy. Every client needs AI in some form or another, specifically, some sort of LLM (Large Language Model) (aka. ChatGPT for the non-technical folks reading this). But thanks to small efficient LLM models like Google's Gemini Nano and Microsoft's Phi-3 we can even run those with less resources.
But we still to need to face the facts, data is still crucial even if we have a very bad algorithm. But we do have some solutions for that too. But before you go to that, lets go back to the problem at hand.
"Building a MLOps Solution a Cheap as Possible"
A short introduction on MLOps, it's where ML Engineers Collaborate, Experiment and Deploy AI/ML stuff, the same as our problem statement, but what does this got to do with Frugal AI you ask? Well if we can get to run our MLOps cheaply then we are pretty much covered on using less resources for all the compute needs of our AI/ML projects.
We choose Kubeflow for our MLOps, Kubeflow is an open-source platform designed to make it easy to deploy, manage, and scale machine learning (ML) workflows on Kubernetes. It provides a comprehensive suite of tools and components to support every stage of the ML lifecycle, from data preparation to training, tuning, deployment, and monitoring of models.
The core idea behind Kubeflow is to leverage Kubernetes' powerful orchestration capabilities to manage complex ML workflows, ensuring they are scalable, portable, and reproducible. Kubeflow integrates with popular ML frameworks like TensorFlow, PyTorch, and Scikit-learn, making it easier for data scientists and engineers to build, test, and deploy models in a production environment.
Some key features of Kubeflow include,
- Pipelines: To define, manage, and automate end-to-end ML workflows.
- Training and Hyperparameter Tuning: Tools to run distributed training jobs and automatically search for the best model parameters.
- Model Serving: Capabilities for deploying models as microservices, with support for scaling and monitoring.
- Notebooks: Integration with Jupyter notebooks for an interactive development experience.
Overall, Kubeflow is a powerful tool for organizations looking to streamline their ML operations by leveraging the scalability and robustness of Kubernetes.
Another thing you should know about Kubernetes is that, it is too damm expensive to run it for the scale required by Kubeflow in Azure, GCP or AWS. So we need to think outside of the box, out of the industry standard, something more predictable and cheap.
.png)
I took the decision to go with a sort of on-premises k8s cluster, I know this puts more stress on the team but I personally worked on this part for the team, and the best part is I don't even have any certifications or experience with Kubernetes, but I'm a fast learner. Another proof to not have a fixed mindset (most people are in tutorial hell and think that certification means everything which in reality is just a thing to get your foot on the door).
We choose a very cheap cloud provider, a trust worthy one but still cheap and has very predictable pricing, there will be article on the specifics soon but I leave this as a suspense for now. All I could say is that, with this cloud provider we were able to run a fully functional k8s cluster for Kubeflow under just $300 per month which would easily cost $3000 on Azure, GCP or AWS.
With Kubeflow in place, with 5+ engineers on our AI/ML team, we were doing experiments without the worry about bankrupting our company which is great if you ask me, the solution is not only cheap but also does not exceed a specific threshold we fixed.
But What About Data?
Yeah, as I said, the fact is, data is still very important factor for AI/ML models and even experimentation. Thanks to the rise of LLMs and efficient LLM models we can synthesize it too but before we bring the big guns, we like to introduce a wonderful project from our folks at MIT, "The Synthetic data vault". This is a interesting paper you can read it from here. If you want to see the code, it's also open-source.
We use this wonderful project to make synthetic data, but we try a lot to get datasets from challenges over at Kaggle or some standard competitions, but sometimes, for specific needs we use synthetic data. It's also cheaper because it uses less resources to generate them.
More Insights

Illuminating the Role of the People Manager in SAFe: From Traditional Oversight to Empowered Enablement
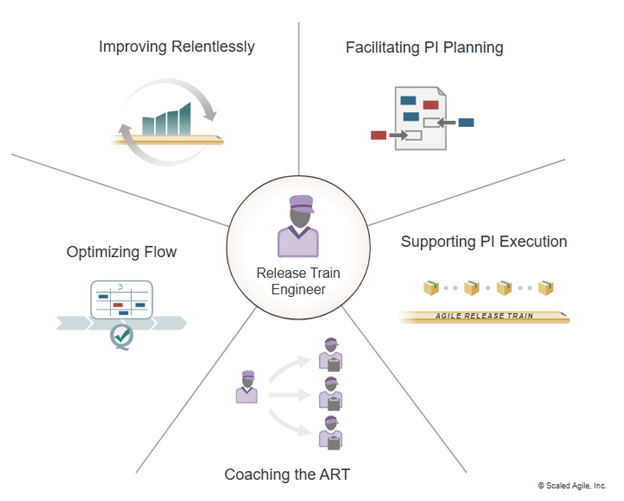
Demystify Role of RTE in SAFe

Revolutionizing Customer Experience with Generative AI: Personalization at Scale